

Recentemente precisei fazer um estudo de caso onde era necessário prever o índice de crimes em uma determinada localidade para os próximos 6 meses. Pesquisando sobre os diferentes métodos disponíveis para fazer essa previsão eu encontrei e elegi Time-Series Forecast (Previsão de Série Temporal), para realizar o estudo. O problema é que eu nunca havia feito qualquer atividade utilizando esse método, então o próximo passo foi pesquisar sobre o assunto e após ler vários artigos sobre eu cheguei até a biblioteca Prophet criada pelo Facebook. De longe foi a biblioteca mais simples e direta de usar que encontrei e então resolvi tentar e o resultado foi bem satisfatório.
No exemplo deste post vou utilizar o mesmo dataset de crimes para descrever minha linha de raciocínio, passando pela AED até chegar ao TS Forecast e ao resultado final. Irei utilizar o Jupyter Notebook para codificação com Python 3.6.3.
Instalação da biblioteca:
pip install fbprophetBem simples, não?
Importação das bibliotecas necessárias:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# Apenas porque eu acho mais bonito :)
plt.style.use('fivethirtyeight')Leitura do arquivo de dados:
%%time
df = pd.read_csv('./Crimes_2011_to_present.csv', index_col=False, error_bad_lines=False, engine='python')
# CPU times: user 29.1 s, sys: 1.69 s, total: 30.8 s
# Wall time: 31.4 sExplicando os parâmetros:
index_col=False: utilizado para o Pandas não utilizar o ID do dataset como índice.
error_bad_lines=False: utilizado para caso a leitura do dataset encontre alguma linha com problema ele simplesmente ignorar.
engine=’python’: utilizado apenas por é hábito. No caso de números decimais contidos no dataset ele já importa com o número de casas “as-is”
Remoção de features que não será utilizadas:
df.drop(['Case.Number', 'IUCR', 'X.Coordinate', 'Y.Coordinate', 'Block', 'Updated.On', 'Year', 'FBI.Code', 'Beat', 'Ward', 'Community.Area', 'Location'], inplace=True, axis=1)Para facilitar a vida no futuro eu converti a coluna Date para o time correto e “setei” a mesma para ser o índice do meu dataset:
df['Date'] = pd.to_datetime(df['Date'])
df.index = pd.DatetimeIndex(df['Date'])Algumas outras preparações para realizar as análises:
# Criei duas novas colunas de Ano e Mês
df['Year'] = pd.DatetimeIndex(df['Date']).year
df['Month'] = pd.DatetimeIndex(df['Date']).month
# Converti o datatype de duas colunas para booleano
df['Arrest'] = df['Arrest'].astype('bool')
df['Domestic'] = df['Domestic'].astype('bool')
# NaN se não converter
df['Latitude'] = pd.to_numeric(df['Latitude'], errors='coerce')
df['Longitude'] = pd.to_numeric(df['Longitude'], errors='coerce')
df['District'] = pd.to_numeric(df['District'], errors='coerce')
# Remove os NaN
df = df[df['Latitude'].notnull()]
df = df[df['Longitude'].notnull()]
df = df[df['District'].notnull()]
# Seleciona as top 20 entradas
loc_to_change = list(df['Location.Description'].value_counts()[20:].index)
desc_to_change = list(df['Description'].value_counts()[20:].index)
# Função auxiliar para converter para 'OTHER' o que não estiver nos top 20
def parse_location_names(location):
if location in loc_to_change:
return 'OTHER'
else:
return location
df['Location.Description'] = df['Location.Description'].map(parse_location_names)
# Outra forma para converter para 'OTHER'o que não estiver nos top 20
df.loc[df['Description'].dropna().isin(desc_to_change), df.columns == 'Description'] = 'OTHER'
# Converte features para o tipo categórico
df['Primary.Type'] = pd.Categorical(df['Primary.Type'])
df['Description'] = pd.Categorical(df['Description'])
df['Location.Description'] = pd.Categorical(df['Location.Description'])Exploração e Visualização
plt.figure(figsize=(11, 5))
df.resample('M').size().plot(legend=False)
plt.title('Number of crimes per month (2011 - 2015)')
plt.xlabel('Months')
plt.ylabel('Number of crimes')
plt.show()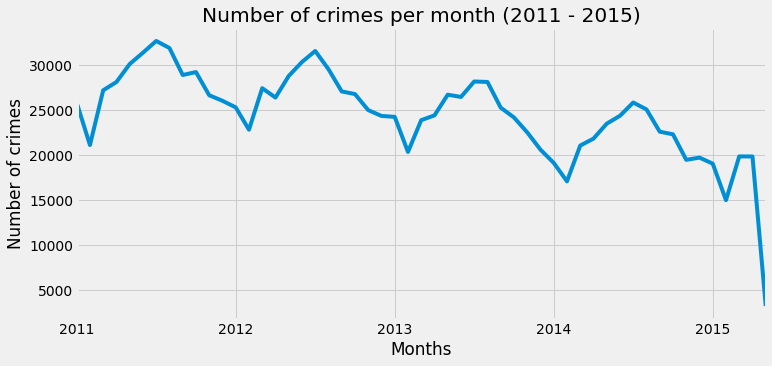
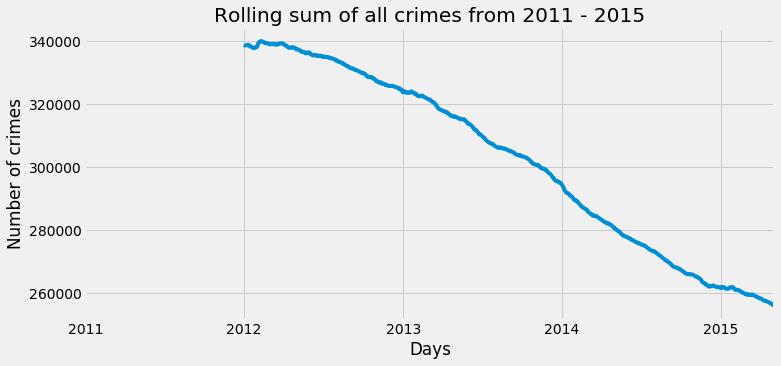
plt.figure(figsize=(11, 5))
df.resample('D').size().rolling(365).sum().plot(legend=False)
plt.title('Rolling sum of all crimes from 2011 - 2015')
plt.ylabel('Number of crimes')
plt.xlabel('Days')
plt.show()
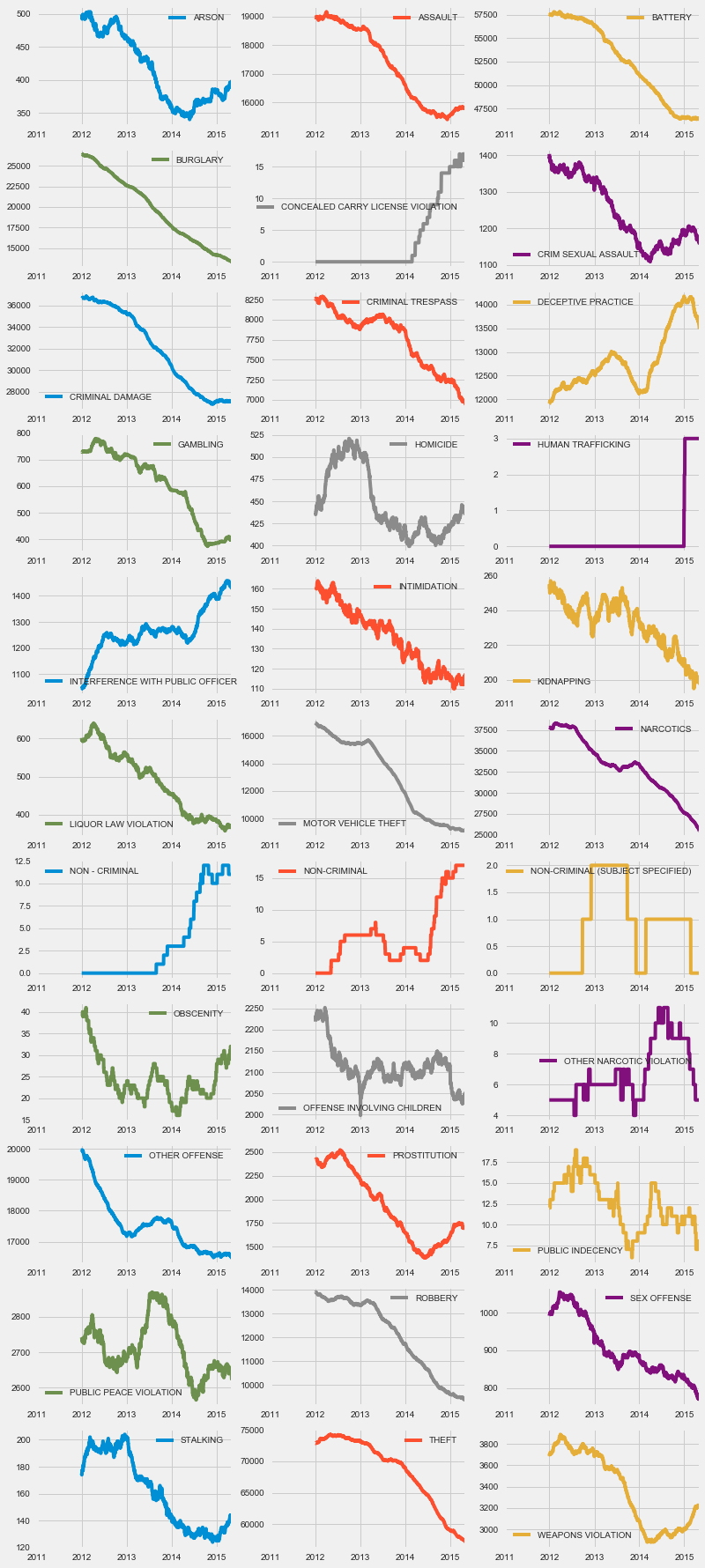
crimes_count = df.pivot_table('ID', aggfunc=np.size, columns='Primary.Type', index=df.index.date, fill_value=0)
crimes_count.index = pd.DatetimeIndex(crimes_count.index)
plo = crimes_count.rolling(365).sum().plot(figsize=(12, 30), subplots=True, layout=(-1, 3), sharex=False, sharey=False)
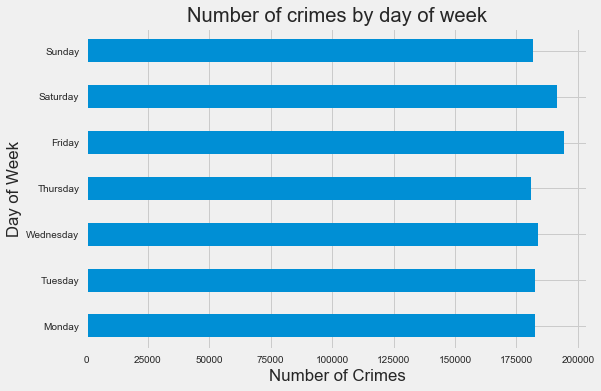
days = ['Monday','Tuesday','Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']
df.groupby([df.index.dayofweek]).size().plot(kind = 'barh')
plt.title('Number of crimes by day of week')
plt.xlabel('Number of Crimes')
plt.ylabel('Day of Week')
plt.yticks(np.arange(7), days)
plt.show()
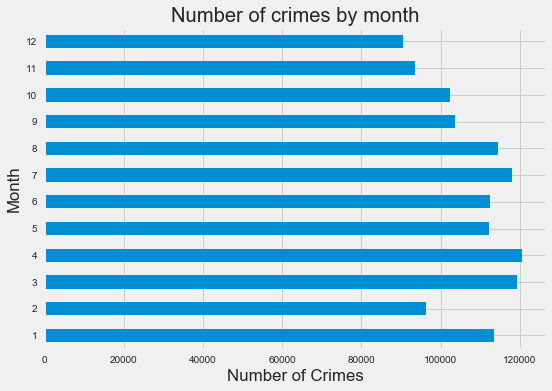
df.groupby([df.index.month]).size().plot(kind = 'barh')
plt.title('Number of crimes by month')
plt.xlabel('Number of Crimes')
plt.ylabel('Month')
plt.show()
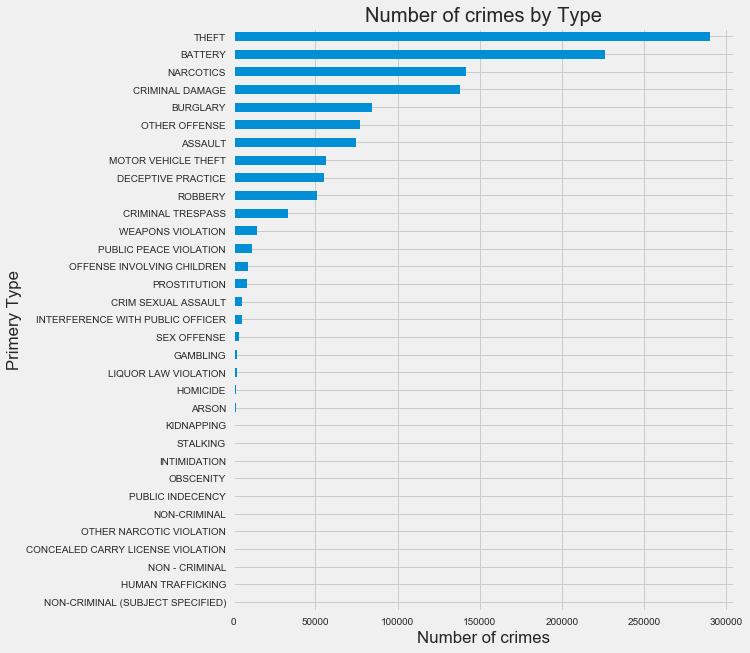
plt.figure(figsize=(8, 10))
df.groupby([df['Primary.Type']]).size().sort_values(ascending=True).plot(kind = 'barh')
plt.title('Number of crimes by Type')
plt.xlabel('Number of crimes')
plt.ylabel('Primery Type')
plt.show()
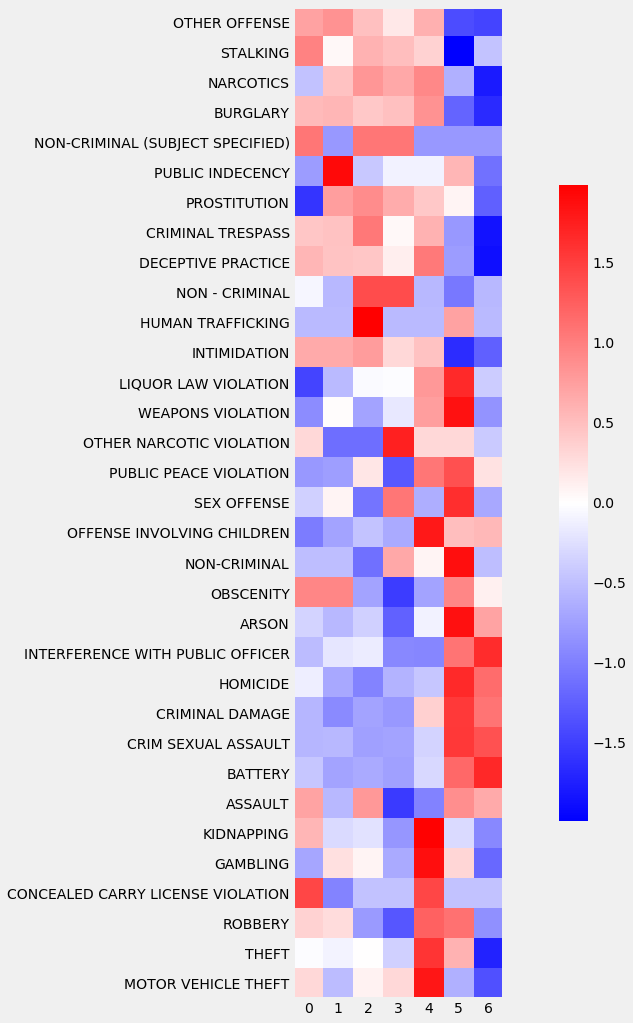
def scale_df(df,axis=0):
return (df - df.mean(axis=axis)) / df.std(axis=axis)
def plot_hmap(df, ix=None, cmap='bwr'):
if ix is None:
ix = np.arange(df.shape[0])
plt.imshow(df.iloc[ix,:], cmap=cmap)
plt.colorbar(fraction=0.03)
plt.yticks(np.arange(df.shape[0]), df.index[ix])
plt.xticks(np.arange(df.shape[1]))
plt.grid(False)
plt.show()
def scale_and_plot(df, ix = None):
df_marginal_scaled = scale_df(df.T).T
if ix is None:
ix = AC(4).fit(df_marginal_scaled).labels_.argsort() # a trick to make better heatmaps
cap = np.min([np.max(df_marginal_scaled.as_matrix()), np.abs(np.min(df_marginal_scaled.as_matrix()))])
df_marginal_scaled = np.clip(df_marginal_scaled, -1*cap, cap)
plot_hmap(df_marginal_scaled, ix=ix)
def normalize(df):
result = df.copy()
for feature_name in df.columns:
max_value = df[feature_name].max()
min_value = df[feature_name].min()
result[feature_name] = (df[feature_name] - min_value) / (max_value - min_value)
return result
dayofweek_by_location = df.pivot_table(values='ID', index='Location.Description', columns=df.index.dayofweek, aggfunc=np.size).fillna(0)
dayofweek_by_type = df.pivot_table(values='ID', index='Primary.Type', columns=df.index.dayofweek, aggfunc=np.size).fillna(0)
location_by_type = df.pivot_table(values='ID', index='Location.Description', columns='Primary.Type', aggfunc=np.size).fillna(0)
from sklearn.cluster import AgglomerativeClustering as AC
plt.figure(figsize=(17,17))
scale_and_plot(dayofweek_by_type)
df2 = normalize(location_by_type)
ix = AC(3).fit(df2.T).labels_.argsort() # a trick to make better heatmaps
plt.figure(figsize=(17,13))
plt.imshow(df2.T.iloc[ix,:], cmap='Reds')
plt.colorbar(fraction=0.03)
plt.xticks(np.arange(df2.shape[0]), df2.index, rotation='vertical')
plt.yticks(np.arange(df2.shape[1]), df2.columns)
plt.title('Location frequency for each crime')
plt.grid(False)
plt.show()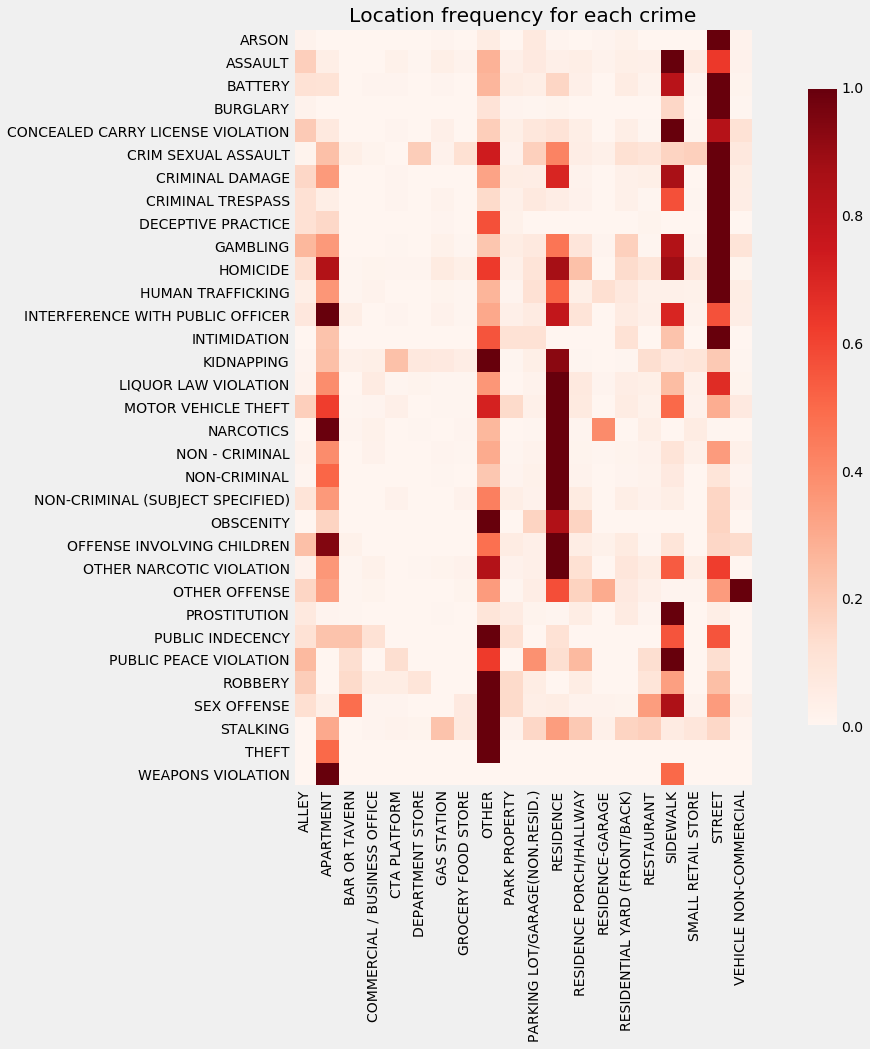
TS Forecast Using Prophet
from fbprophet import Prophet
fc_df = df[['District']]
fc_df.reset_index(inplace=True)
fc_df = df.groupby(['Date', 'District']).size()
fc_df = fc_df.reset_index()
fc_df.columns = ['ds', 'District', 'y']
# Foi escolhido o distrito 1.0 para realizar o forecast
# =====================================================
aux = fc_df[fc_df['District']==1.0]
aux = aux[['ds', 'y']]
ax = aux.set_index('ds').plot(figsize=(16, 8))
ax.set_ylabel('Number of Crimes')
ax.set_xlabel('Date')
plt.show()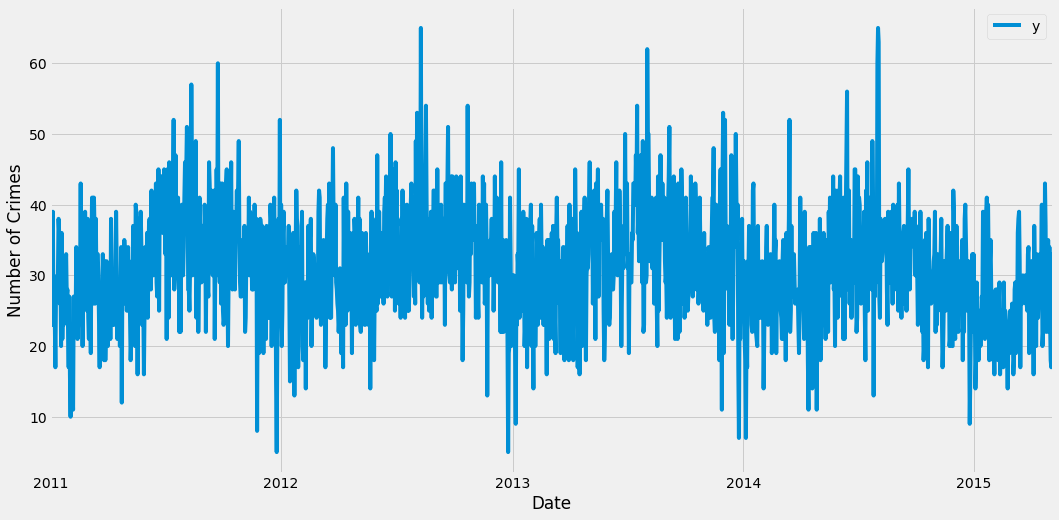
my_model = Prophet()
my_model.fit(aux)
future_dates = my_model.make_future_dataframe(periods=6, freq='MS')
forecast = my_model.predict(future_dates)
forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()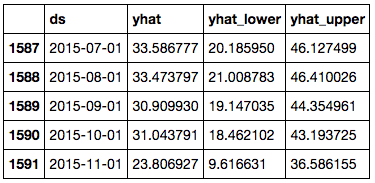
my_model.plot(forecast, uncertainty=True)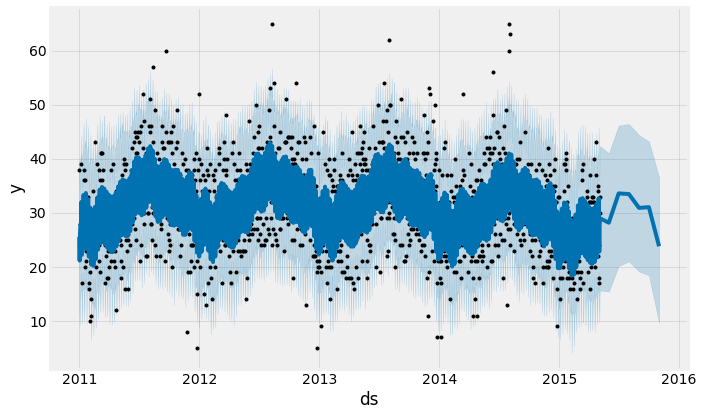
my_model.plot_components(forecast)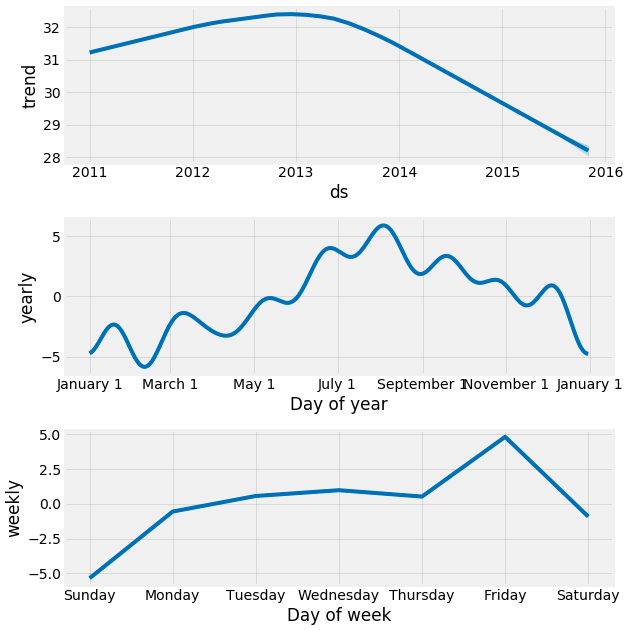
Cross Validation
from fbprophet.diagnostics import cross_validation
df_cv = cross_validation(my_model, horizon = '365 days')
df_cv.head()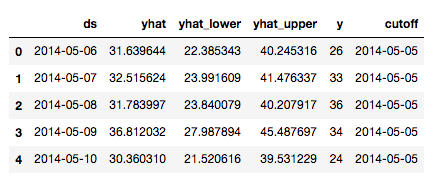
df_cv[['y', 'yhat']].plot(figsize=(16, 6))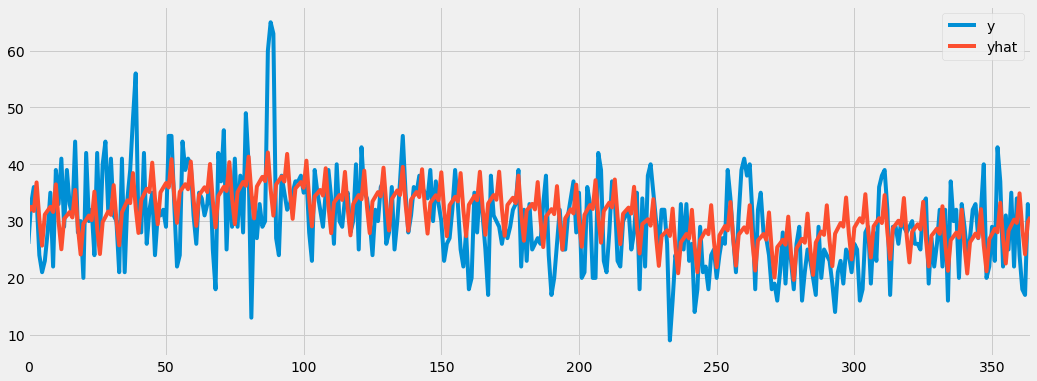
y = dado real / yhat = previsão
Então é isso. Nós podemos continuar com as otimizações do nosso modelo aplicando sazonalidade ao treino, alterando o período, precisão, etc.
Nós próximos posts trarei mais exemplos com outros modelos de TS, regressão, classificação, clusterização, RNA (será?!).